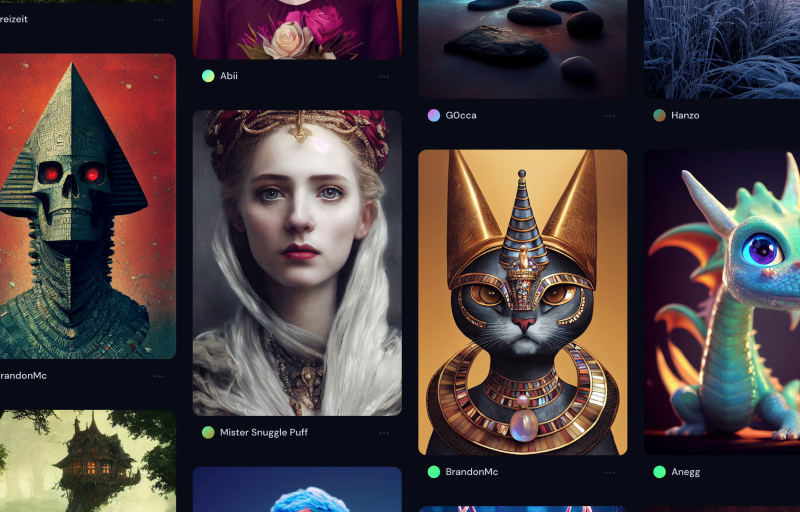
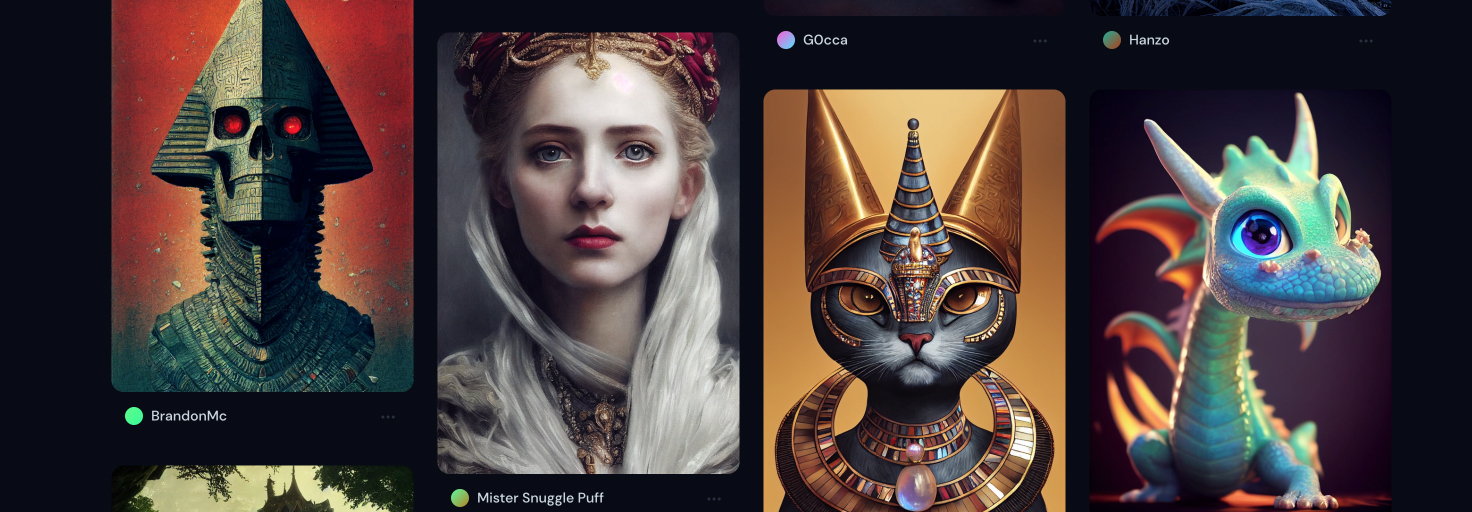

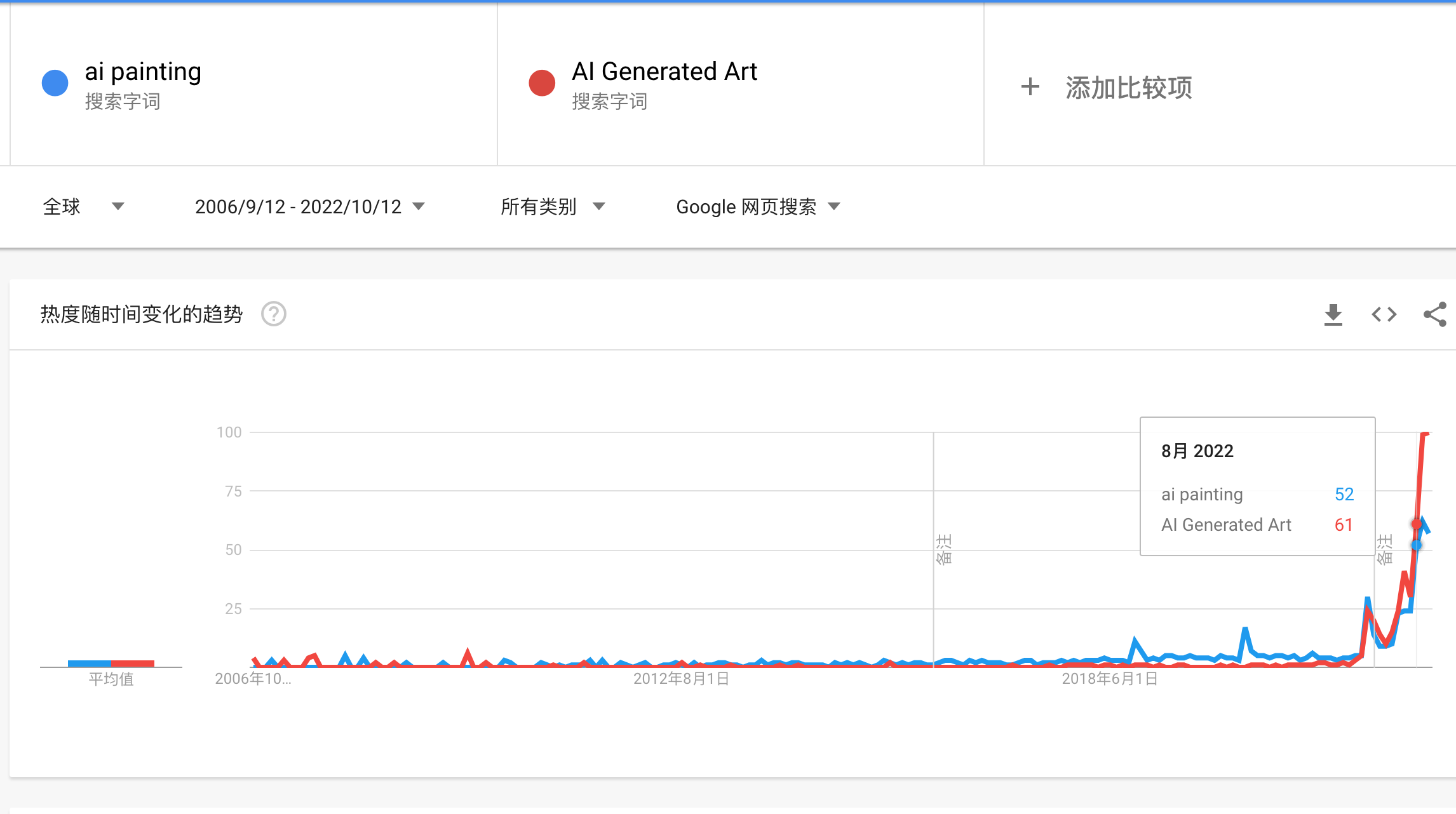
今年 AI 生成艺术或者说是 AI 绘画有了爆发性增长,在谷歌指数中可以看到其惊人的上升曲线,它在以前所未有的惊人的速度从学术界扩散到大众视野 ,可以说 2022 年是 AI 生成艺术的元年。
这背后带来了很多的变化与争议,这里我们就作为「设计类软件开发者」、「 UI 设计师」、「平面设计师」、「非专业绘画爱好者」的身份在这个 AI 生成艺术的元年一起来聊一聊 AI 生成艺术和其相关的争议话题,希望结合多方面的视角,更全面的认识 AI 生成艺术,并预测一下它可能带来的变化。
背后的技术原因
AI 生成艺术爆发背后主要的技术原因是 Diffusion Model (扩散模型) 在这 2 年的发展,突破了 AI 生成艺术多年以来的技术瓶颈,结合已经发展得很成熟了的文本语言模型 GTP-3 ,带来了可用性极高的文本生成图片工具
GAN(生成对抗网络) 的瓶颈
上一代 AI 生成艺术的基于 GAN (生成对抗网络, GAN 的发展简史),简单来说就是使用 2 个神经网络:一个作为生成器一个作为判别器,生成器生成不同的图像让判别器去判断结果是否合格,二者互相对抗以此训练模型。
GAN(生成对抗网络)经过不断发展其有了不错的效果,但有些始终难以克服的问题:生成结果多样性缺乏、模式坍缩(生成器在找到最佳模式后就难以进步了)、训练难度高。 这些困难导致 AI 生成艺术一直难以做出实用的产品。

Diffusion Model(扩散模型) 的突破
在 GAN 多年的瓶颈期后,科学家想出了非常神奇的 Diffusion Model (扩散模型) 的办法去训练模型:
把原图用马尔科夫链将噪点不断地添加到其中,最终成为一个随机噪声图像,然后让训练神经网络把此过程逆转过来,从随机噪声图像逐渐还原成原图,这样神经网络就有了可以说是从无到有生成图片的能力。而文本生成图片就是把描述文本处理后当做噪声不断添加到原图中,这样就可以让神经网络从文本生成图片。

Diffusion Model (扩散模型) 让训练模型变得更加简单,只需大量的图片就行了,其生成图像的质量也能达到很高的水平,并且生成结果能有很大的多样性,这也是新一代 AI 能有难以让人相信的“想象力”的原因。
在 Diffusion Model (扩散模型) 诞生短短 2 年内,就把 AI 生成艺术带到了可用的程度:
- 这篇 2020 年的论文 Denoising Diffusion Probabilistic Models ,首次把2015 年诞生的扩散模型用在了图像生成上
- 2021 年 1 月 openAI 公布了 Dall-E 并在 论文中宣布 Diffusion Model (扩散模型) 击败了 GAN (生成对抗网络)(Diffusion Models Beat GANs on Image Synthesis),为工程界指明了方向。
- 2021 年 10 月开源的文本生成图像工具 disco-diffusion 诞生,此后有相当多的基于此的产品出现。
- 2022 年 8 月 stability.ai 开源了 Stable Diffusion , 这是目前可用性最高的开源模型,很多商业产品都基于此如: NovelAI

AI 生成艺术对绘画的冲击
随着 AI 生成艺术工具的成熟,最近无论是绘画爱好者还是平面设计师,AI 生成对行业会不会造成冲击,AI 会不会取代艺术家成为了备受争议的话题。不过在人们讨论的同时, AI 生成艺术已经开始取代一部分原有的场景下的工作了,所谓「面对汽车,当大多数车夫还在争论汽车有没有用时,聪明的车夫已经在考驾照了」
The Atlantic 这样的新闻网站已经在文章的头图中使用 AI 生成的图片来取代原本「图库」网站中人类的作品了

甚至连「央视新闻」都已经在时事新闻中都使用 AI 生成的图片

很可能在更多不注意的角落,AI 生成的作品已经开始被使用了,而大家却还不知道,这意味着一件重要的事实:大众已经无法分辨 AI 生成作品与纯手工作品了,虽然高质量的艺术创作还很难用 AI 取代,但 AI 生成作品的效率足够高,在大部分日常消费艺术作品(插画、封面、海报)中使用 AI 生成的素材是非常有吸引力的事情。对于艺术创作者而言,不得不承认的使用 AI 生成工具会慢慢的成为创作者必备的技术之一。
对 AI 的抵触情绪
因为 AI 对于大部分人而言都是难以真正理解的,所以人们会用各种各样的角度看待 AI,其中不乏很多抵触的声音

我认为在目前国内偏保守的氛围下,这是声音是需要关注的,他们类似于 「新卢德主义者」,核心是因为害怕 「劳动机会的缺乏」而抵触新技术的群体,他们会「自发」的出现,虽然我认为这个时代已经不可能会有新的「卢德运动」,但是要考虑到如果经济环境不好,产生这些群体的土壤会增加,届时在 AI 技术的宣传与推广上就得考虑到这部分人的存在, 避免产生一些争议。

版权与垄断
与很多艺术工作者把「AI 当做敌人」把「版权当成保护自己的武器」的观点不一样,在我看来「过于严苛的版权保护将会造成大公司对 AI 的垄断与对创作者的过度剥削」。
研发 AI 生成艺术工具需要大量的「数据」来训练模型,可以说对于 AI 来说「技术」大家最终总会趋于接近,而「数据」才是最重要的资源,对于大公司而言最佳的环境就是对任何艺术作品都进行严格的法律保护,不允许用作 AI 模型的训练,这样大公司就可以运用其资金优势购买艺术作品版权用作数据集制造出效果最好的的 AI 艺术生成工具,这样大公司就可以垄断 AI 艺术生成工具,而垄断的成本由谁支付呢?当然是由创作者们支付,这样创作者只能面对必须高价购买大公司的 AI 工具或者被别的购买了 AI 工具的创作者淘汰的场面。
这在其他领域已经发生过了,现在任何人都能从网络得到上免费开源的可用性极高的人脸识别 AI 工具,因为人脸照片是非常易得的数据源。而医药研发的 AI 工具则被少数的大公司垄断,因为没有人能轻易得到昂贵的医药研发数据。
当然我不是在说不对作品做任何限制与保护才是对的,而是想表达这是一个非常复杂的问题,「简单的严格保护版权」并不是对创作者最有利的选择,因为 AI 生成艺术能释放的生产力实在太大了,生产关系可能需要做出一些改变。

从事实上来说,现在的 AI 生成工具并不是有些人想象中的存储了大量的图片数据然后用某些规则去「拼合」,AI 所用的模型是使用数据集去「训练」产生的,而不是数据本身,用几千 TB 的数据源去训练最终可能只得到几 GB 的模型,大小只有数据集的百万分之一,而使用这个模型生成新作品并不能用简单的「拼合」去理解。
并且人们几乎不可能去判断一个巨大的数据集一定用了某张图去训练,而人类也很难去分辨一张图是否是使用 AI 去创作或者有 AI 参与创作,也就是说只能当做普通作品去看待,看最终的作品有没有侵犯版权。
AI 艺术生成工具取代图库
与版权相关的另一个问题是,AI 生成艺术工具可以取代视觉中国、Shutterstock 、Getty 这样的图库,事实上相比画师们他们才是对 AI 版权的法律判断影响更大的因素,AI 生成工具非常有机会取代他们,版权是唯一的问题,拥有大量图片版权的他们会倾向于阻止 AI 使用图片训练模型。
图片真实性危机
另一个 AI 生成艺术的争议是图片真实性的危机,以前虽然有 Photoshop 甚至胶片时代也有「暗房技术」来制造假图片,但是始终有不小的技术门槛,但是 AI 生成艺术工具让生成假照片的门槛降低了很多,并且 AI 生成的图片很可能比真实照片更有表现力,更利于传播,现在已经有很多时事新闻中的图片是用 AI 生成的了
AI 能不能作用于 UI 设计
有的人认为现在 AI 生成艺术虽然看起来「想象力丰富」但却不「精确」不「稳定」,并不适合 UI 创作。但我觉得这其实是「工程」问题而非是 AI 的能力限制。
目前生成图片的 AI 除了生成插画,确实不太适合 UI 设计,因为 UI 设计非常的结构化,神经网络确实很难去「理解规则」,但现实中还会有神经网络与规则算法协作的办法,让 AI 生成「精确」的设计图理论上不存在问题。
而且实际上还有更 UI 合适的模型,就是像 Github Copilot 一样,把 UI 设计当做结构化的语法,根据上下文去补全,达到设计一半自动生成剩下一半的效果。我觉得 AI 技术走进 UI 设计领域只是时间问题,目前还没有相关产品可能是因为 UI 设计的结构化数据集比较缺乏,可能只有 Figma 这样拥有大量用户设计图原始数据的厂商才能训练出可靠的模型。
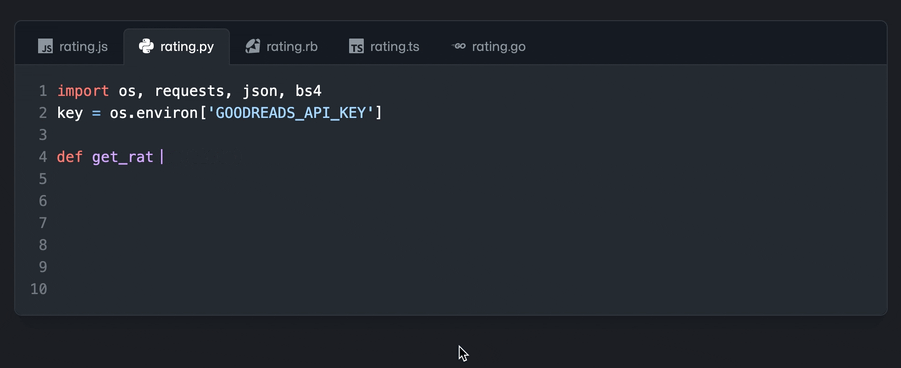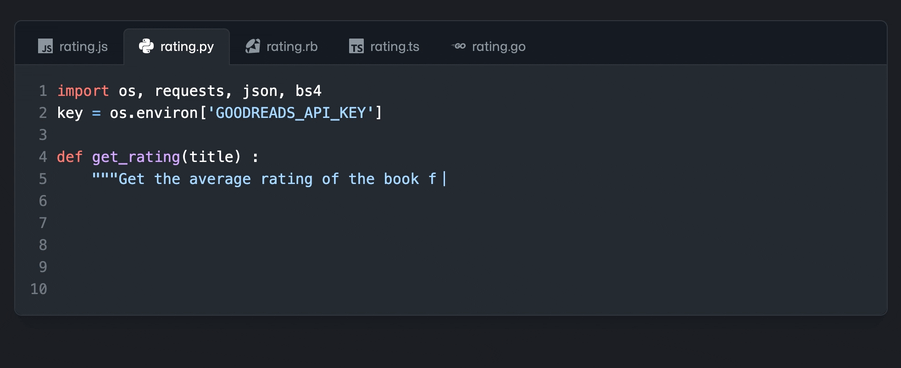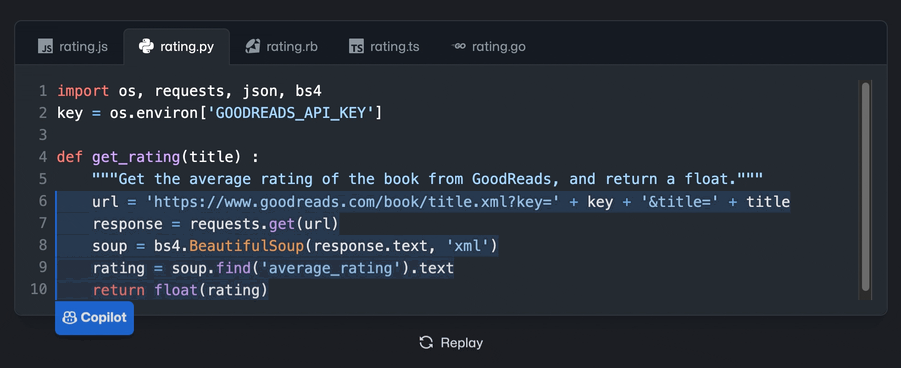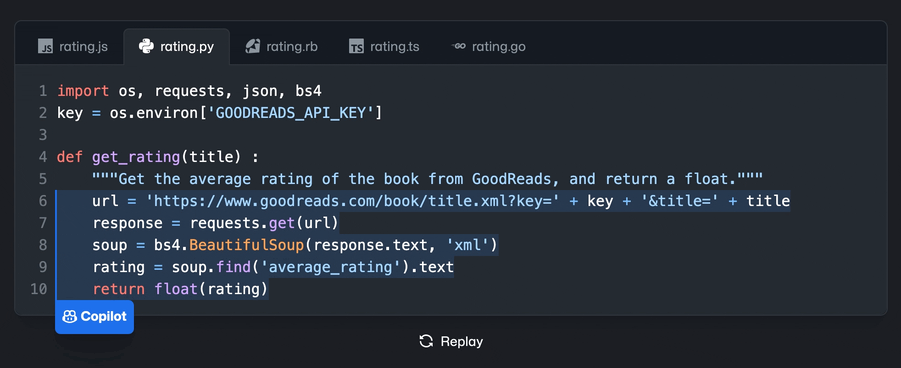
未来的预测
人们总是高估新技术在 3 年内的发展,却又低估其在 10 年后的影响 —— 阿玛拉定律

AI 生成艺术从 2014 真正开始起步,花了快 10 年时间迎来了技术突破,影响力进入了指数型的增长,非常不容易,因为技术门槛较低(有高质量的开源实现),接下来的一年里会有非常多的 AI 生成艺术的产品出现,但生成的质量可能并不会在短期有较大的提升,也就是说并不会达到轻易取代人工的地步,使用门槛还是有的,毕竟这次的 AI 生成艺术爆发的原因来自 Diffusion Model (扩散模型),它解决了 AI 生成的多样性的问题,但还有很多问题等待下一次技术突破,比如对内容逻辑的形式化理解、模型训练的可控性。不过 AI 生成艺术工具的实用性在短时间内很可能会有很大提升,真是无比期待下一个 10 年。
速度
AI 生成技术有一个不可能三角:质量、速度、多样性,目前的 Diffusion Model (扩散模型) 着力在质量与多样性上,而速度则是个问题,所以目前的 AI 艺术生成工具的生成速度都非常慢,几十秒甚至几分钟才能出图,虽然比人手工画可快多了,但是由于生成结果的不可预期性,人们需要反复尝试,体验不佳,接下来随着 AI 生成艺术工具的发展,速度一定会得到提升,当能做到输入内容一秒内就能预览到多个结果时,AI 生成艺术工具就会真正改变艺术创作流程。
提示词(Prompt)
另一个会影响 AI 生成工具体验的是提示词,也就是操作 AI 生成绘画的方式,现在 AI 生成艺术依赖的提示词还非常原始和难以操控,甚至写提示词的过程还被称为提示工程(Prompt Engineering),得非常有经验才能生成想要的内容。为了更好的写提示词,还出现了 promptbase 这样贩卖提示词的市场,和很多生成提示词的辅助工具。
未来如何操作 AI 生成绘画将会是 AI 生成工具的重要提升点,除了直接增加提示词的可用性,二次编辑、从草图生成、编辑细节等功能都亟待实现,这些是工程问题,只要时间就可以实现。
可以想象会出现一个类似 Github Copilot 的 AI 帮助你编写提示词去操纵另一个 AI 生成图片
绘画辅助工具
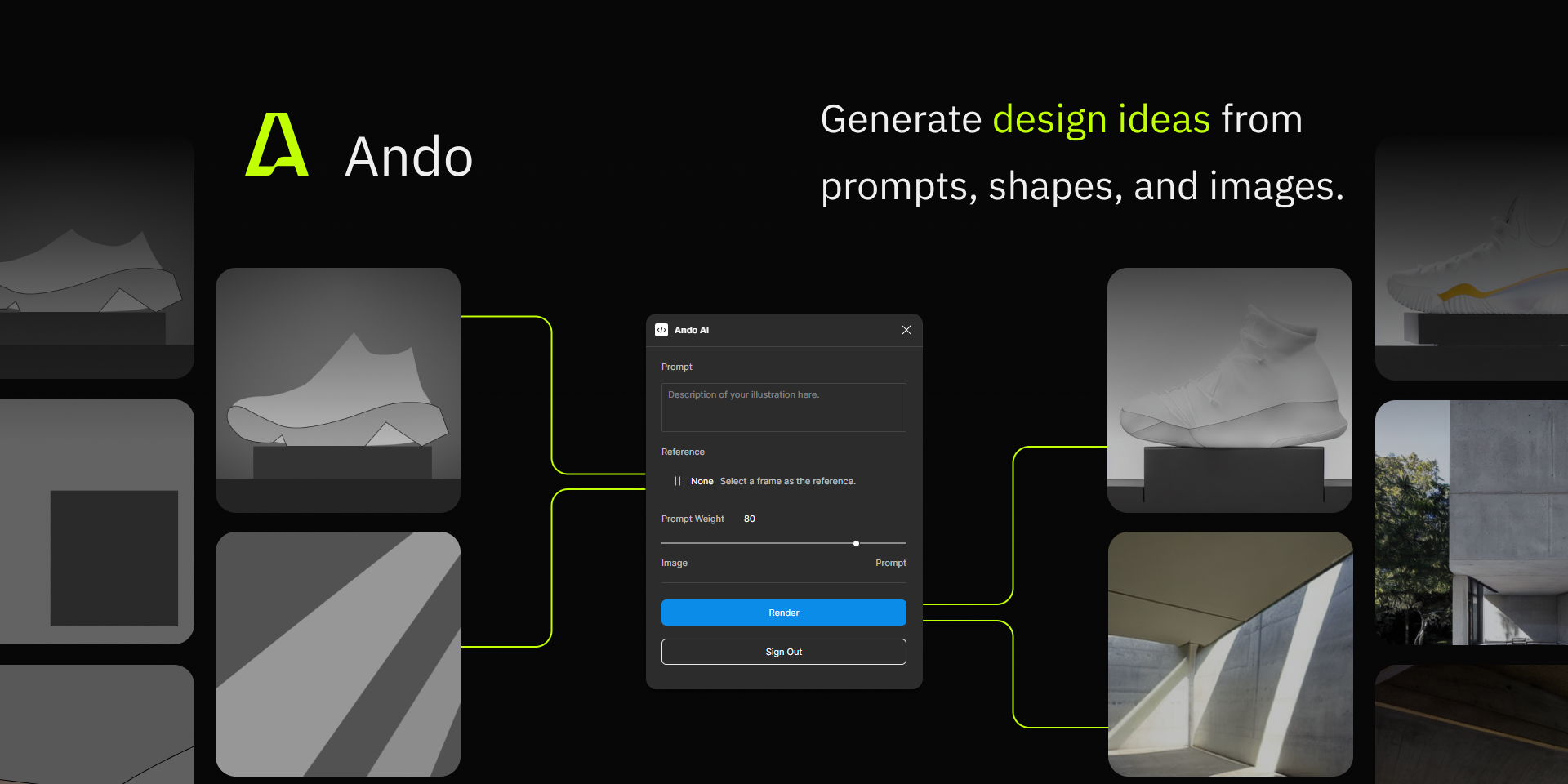
现在的 AI 生成工具大多面向普通人,针对创作者群体的工具也有很大的发展空间,比如根据已完成内容完成剩下的内容、根据现有作品拓展不同的版本、指导下一步可能的操作这样融入创作工作流的工具。比如 Figma 的 Ando 插件就是一个例子
AI 生成视频
既然 AI 可以生成图片,那生成视频自然将会成为下一个待开垦的地带,现在也已经有一些初级尝试了比如:phenaki.video 和 Meta 的 Make A Video

AI 生成 3D 模型
视频有了,3D 模型也不能少,现在也有一些初期尝试 dreamfusion3d

最后...
有些绘画爱好者认为绘画艺术重要的是过程的体验,AI 可以生成优秀的「作品」,但它无法取代创造艺术的体验和乐趣,而创作者体验这些的过程就是艺术的美,这种看法或许有些狭隘了,如果把绘画当做描绘内心与表达自我的一种手段,AI 生成其实也是一种手段, AI 艺术创作者也会在使用 AI 的过程中得到自己的「心流体验」,体会到用 AI 创作的乐趣与艺术的美。
AI 生成艺术,会让更多的人去思考「艺术」的意义与 「人与艺术的关系」。绘画不是一成不变的,它从诞生开始就与技术难解难分,化学工业给绘画带了丰富的色彩,让写实成为可能,给与绘画记录历史的意义。而印刷术让大众能学习绘画成为可能。摄影术又剥夺了绘画写实的价值,让绘画重新去关注内心描述与自我表达,而 AI 生成艺术或许会改变更多。





